

how to create an index in sql
Summary: in this tutorial, you will learn how to use the SQL Server CREATE INDEX statement to create nonclustered indexes for tables.
Introduction to SQL Server non-clustered indexes
A nonclustered index is a data structure that improves the speed of data retrieval from tables. Unlike a clustered index, a nonclustered index sorts and stores data separately from the data rows in the table. It is a copy of selected columns of data from a table with the links to the associated table.
Similar to a clustered index, a nonclustered index uses the B-tree structure to organize its data.
A table may have one or more nonclustered indexes and each non-clustered index may include one or more columns of the table.
The following picture illustrates the structure non-clustered index:
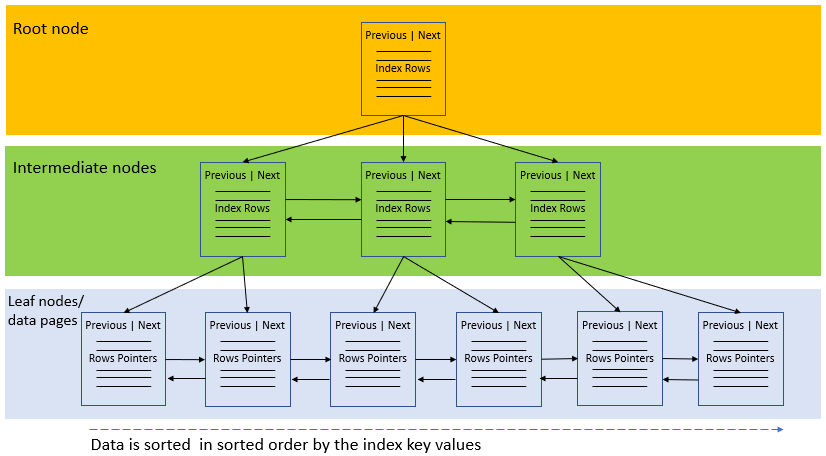
Besides storing the index key values, the leaf nodes also store row pointers to the data rows that contain the key values. These row pointers are also known as row locators.
If the underlying table is a clustered table, the row pointer is the clustered index key. In case the underlying table is a heap, the row pointer points to the row of the table.
SQL Server CREATE INDEX statement
To create a non-clustered index, you use the CREATE INDEX statement:
Code language: SQL (Structured Query Language) ( sql )
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column_list);
In this syntax:
- First, specify the name of the index after the
CREATE NONCLUSTERED INDEXclause. Note that theNONCLUSTEREDkeyword is optional. - Second, specify the table name on which you want to create the index and a list of columns of that table as the index key columns.
SQL Server CREATE INDEX statement examples
We will use the sales.customers from the sample database for the demonstration.

The sales.customers table is a clustered table because it has a primary key customer_id.
A) Using the SQL Server CREATE INDEX statement to create a nonclustered index for one column example
This statement finds customers who locate in Atwater:
Code language: SQL (Structured Query Language) ( sql )
SELECT customer_id, city FROM sales.customers WHERE city = 'Atwater';
If you display the estimated execution plan, you will see that the query optimizer scans the clustered index to find the row. This is because the sales.customers table does not have an index for the city column.
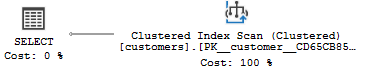
To improve the speed of this query, you can create a new index named ix_customers_city for the city column:
Code language: SQL (Structured Query Language) ( sql )
CREATE INDEX ix_customers_city ON sales.customers(city);
Now, if you display the estimated execution plan of the above query again, you will find that the query optimizer uses the nonclustered index ix_customers_city:

B) Using SQL Server CREATE INDEX statement to create a nonclustered index for multiple columns example
The following statement finds the customer whose last name is Berg and first name is Monika:
Code language: SQL (Structured Query Language) ( sql )
SELECT customer_id, first_name, last_name FROM sales.customers WHERE last_name = 'Berg' AND first_name = 'Monika';

The query optimizer scans the clustered index to locate the customer.
To speed up the retrieval of data, you can create a nonclustered index that includes both last_name and first_name columns:
Code language: SQL (Structured Query Language) ( sql )
CREATE INDEX ix_customers_name ON sales.customers(last_name, first_name);
Now, the query optimizer uses the index ix_customers_name to find the customer.
Code language: SQL (Structured Query Language) ( sql )
SELECT customer_id, first_name, last_name FROM sales.customers WHERE last_name = 'Berg' AND first_name = 'Monika';

When you create a nonclustered index that consists of multiple columns, the order of the columns in the index is very important. You should place the columns that you often use to query data at the beginning of the column list.
For example, the following statement finds customers whose last name is Albert. Because the last_name is the leftmost column in the index, the query optimizer can leverage the index and uses the index seek method for searching:
Code language: SQL (Structured Query Language) ( sql )
SELECT customer_id, first_name, last_name FROM sales.customers WHERE last_name = 'Albert';

This statement finds customers whose first name is Adam. It also leverages the ix_customer_name index. But it needs to scan the whole index for searching, which is slower than index seek.
Code language: SQL (Structured Query Language) ( sql )
SELECT customer_id, first_name, last_name FROM sales.customers WHERE first_name = 'Adam';

Therefore, it is a good practice to place the columns that you often use to query data at the beginning of the column list of the index.
In this tutorial, you have learned about the non-clustered indexes and how to use the SQL Server CREATE INDEX statement to create non-clustered indexes for tables to improve the speed of data retrieval.
how to create an index in sql
Source: https://www.sqlservertutorial.net/sql-server-indexes/sql-server-create-index/
Posted by: hoglundthatounhould.blogspot.com
0 Response to "how to create an index in sql"
Post a Comment